핵심 요약
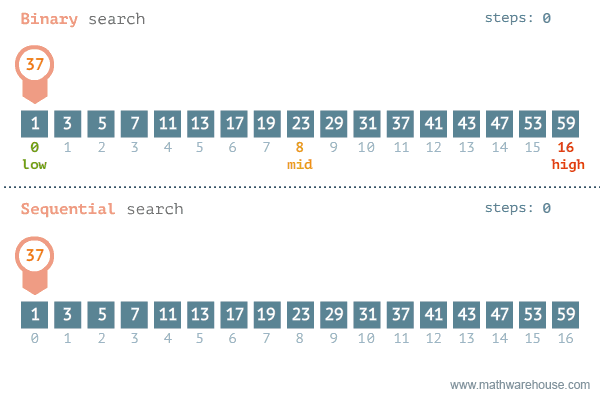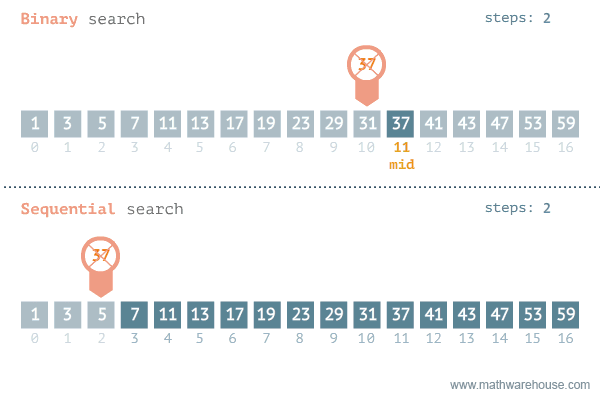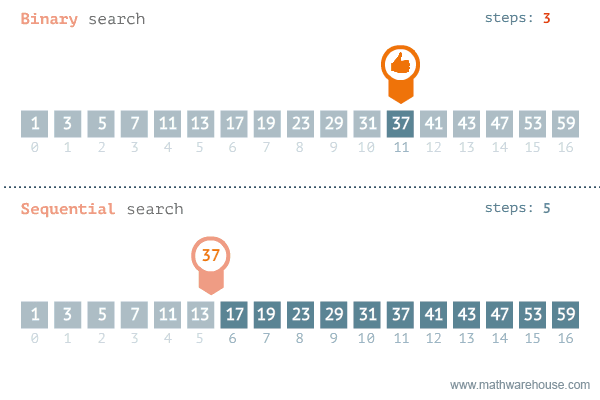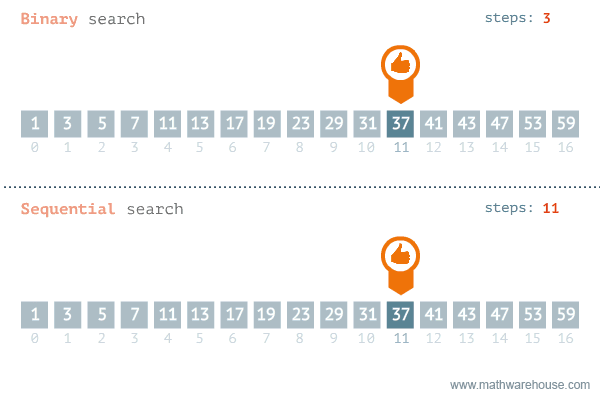
- 이진 탐색이라고도 불리는 이 알고리즘은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이다.
- 그러므로, 배열 내부의 데이터가 정렬이 되어있어야 한다.
- 시간 복잡도는 logN이다.
코드로 구현
- 변수 3개(start, end, mid)를 사용하여 탐색한다.
- 주로 while문을 통해 구성된다.
- 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾는다.
[예제]
N개의 정수 A[1], A[2], …, A[N]이 주어져 있을 때, 이 안에 key라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
찾을 경우 1을 출력, 없을 경우 0을 출력하라.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n, m;
vector <int> v;
int main(void) {
cin>>n;
for(int i = 0; i < n; i++){ //데이터 입력
int num;
cin>>num;
v.push_back(num);
}
sort(v.begin(), v.end()); //정렬
int key;
cin>>key;
int start = 0;
int end = n-1;
int mid;
while(start <= end){
mid = (start+end) / 2;
if(v[mid] == key){
cout<<1;
return;
}else if(v[mid] > key){
end = mid - 1;
}else{
start = mid + 1;
}
}
cout<<0;
return 0;
}'알고리즘을 위한 간략 정리 > 데이터 탐색' 카테고리의 다른 글
| [C++] 매개변수 탐색 (0) | 2023.11.26 |
|---|---|
| 투 포인터(TWO-POINTER) (0) | 2023.10.02 |
| [C++] 이분 탐색(Binary Search) - lower_bound, upper_bound (0) | 2023.09.30 |
