핵심 요약
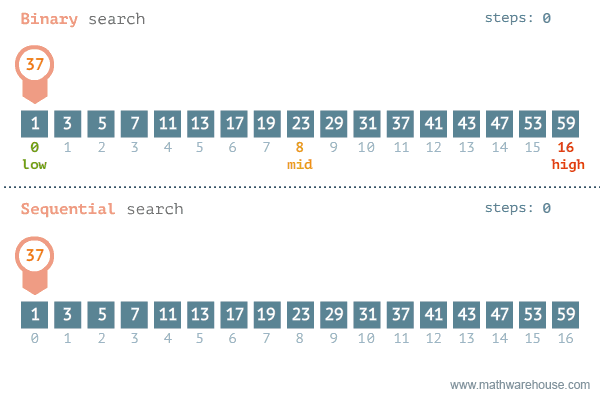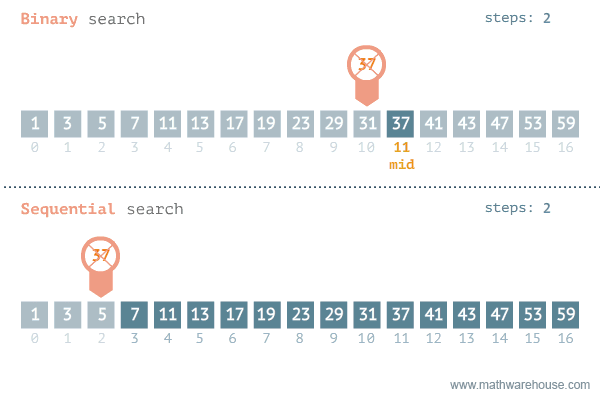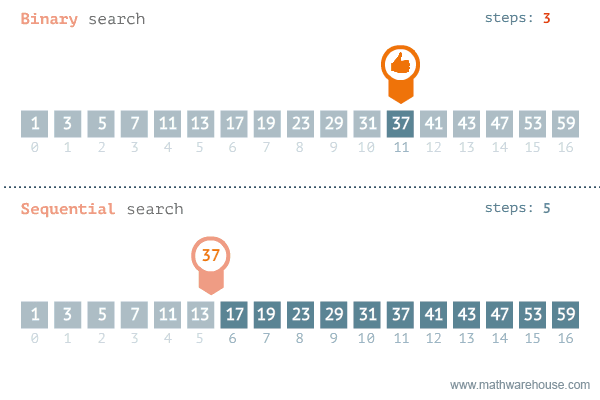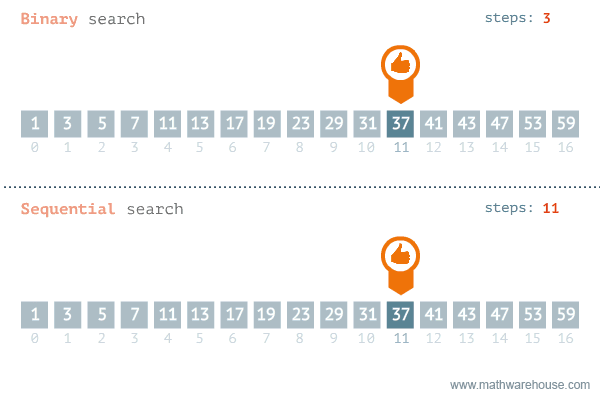
- 이진 탐색이라고도 불리는 이 알고리즘은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이다.
- 그러므로, 배열 내부의 데이터가 정렬이 되어있어야 한다.
- 시간 복잡도는 logN이다.
STL 라이브러리 사용
#include <algorithm> //stl 라이브러리 사용을 위함.
lower_bound(begin(), end(), value);
upper_bound(begin(), end(), value);lower_bound란?
- begin()에서 end()의 범위 중에서 value값 이상이 나타나는 가장 작은 이터레이터를 반환하는 것입니다.
- value가 존재 하지 않는다면 value보다 큰 값 중 가장 작은 값이 나타나는 이터레이터를 반환합니다.
- algorithm 헤더 안에 존재합니다.
- value값 원소의 위치를 찾을 때 사용.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> v;
int main(){
v.push_back(10);
v.push_back(20);
v.push_back(20);
v.push_back(30);
v.push_back(40);
//[0] - 10, [1] - 20, [2] - 20, [3] - 30, [4] - 40
//예제에서는 데이터를 정렬된 상태로 넣었지만, 실제로 사용할 땐 sort 함수를 사용하는 경우가 많다.
int lower_index = lower_bound(v.begin(), v.end(), 20) - v.begin(); //위치를 찾기위해 v.begin()값을 빼줌.
auto lower = lower_bound(v.begin(), v.end(), 20); //주소 값을 찾음.
cout<<"index : "<<lower_index<<"\n";
cout<<"value : "<<*lower<<"\n";
return 0;
}[출력]
index : 1
value : 20upper_bound란?
- begin()에서 end()의 범위 중에서 value 초과 값이 나타나는 가장 작은 이터레이터를 반환하는 것입니다.
- value가 존재 하지 않는다면 value보다 큰 값 중 가장 작은 값이 나타나는 이터레이터를 반환합니다.
- algorithm 헤더 안에 존재합니다.
- value값 원소의 위치를 찾을 때 사용.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> v;
int main()
{
v.push_back(10);
v.push_back(20);
v.push_back(20);
v.push_back(30);
v.push_back(40);
//[0] - 10, [1] - 20, [2] - 20, [3] - 30, [4] - 40
//예제에서는 데이터를 정렬된 상태로 넣었지만, 실제로 사용할 땐 sort 함수를 사용하는 경우가 많다.
int upper_index = upper_bound(v.begin(), v.end(), 20) - v.begin(); //위치를 찾기위해 v.begin()값을 빼줌.
auto upper = upper_bound(v.begin(), v.end(), 20); //주소 값을 찾음.
cout<<"index : "<<upper_index<<"\n";
cout<<"value : "<<*upper<<"\n";
return 0;
}[출력]
index : 3
value : 30'Algorithm' 카테고리의 다른 글
| [C++] 셋(SET) (0) | 2023.10.01 |
|---|---|
| [C++] 원하는 자리수까지 출력하기(반올림, 올림, 내림) (0) | 2023.09.30 |
| [C++] 이분 탐색(Binary Search) - while문 (0) | 2023.09.30 |
| 애드혹(AD-HOC) (0) | 2023.09.30 |
| [C++] 페어(PAIR) (0) | 2023.09.30 |