이 글은 "카프카 핵심 가이드(Kafka: The Definitive Guide)"를 기반으로 작성한 시리즈 포스트입니다.
이 포스트에서는 카프카 컨슈머의 기본 개념, 리밸런스 동작 방식, 그리고 핵심인 폴링 루프를 다룹니다.
1. 컨슈머와 컨슈머 그룹
왜 컨슈머 그룹이 필요한가?
카프카 토픽은 높은 처리량을 위해 여러 파티션으로 나뉩니다. 하나의 컨슈머가 모든 파티션을 처리하면 병목이 생기기 때문에, 카프카는 컨슈머 그룹 단위로 여러 컨슈머가 파티션을 나눠 처리하도록 설계되어 있습니다.
핵심 규칙은 하나입니다.
하나의 파티션은 동일 그룹 내에서 반드시 하나의 컨슈머에게만 할당됩니다.
이 규칙 덕분에 동일 그룹 내 컨슈머들은 중복 없이 메시지를 처리할 수 있습니다.
파티션과 컨슈머 수의 관계

컨슈머 수 ≤ 파티션 수: 각 컨슈머가 하나 이상의 파티션을 담당합니다. 파티션이 남으면 일부 컨슈머가 여러 파티션을 처리합니다.
컨슈머 수 > 파티션 수: 초과된 컨슈머는 어떤 파티션도 할당받지 못하고 유휴(idle) 상태가 됩니다. 장애 대비용으로 의도적으로 두는 경우가 아니라면 낭비입니다.
컨슈머 수를 늘릴 것인가, 그룹 수를 늘릴 것인가?
두 가지는 목적이 다릅니다.
같은 그룹 내 컨슈머 수 증가 → 애플리케이션 처리량 확장
하나의 애플리케이션 내에서 병렬 처리 인스턴스를 늘리는 것입니다. 컨슈머가 추가될수록 각 인스턴스가 담당하는 파티션 수가 줄어들어 처리 속도가 향상됩니다. 파티션 수가 스케일아웃의 상한선이므로, 파티션 수를 넉넉하게 설계하는 것이 중요합니다.
컨슈머 그룹 추가 → 여러 애플리케이션이 독립적으로 소비
그룹이 다르면 같은 토픽의 메시지를 서로 독립적으로 처음부터 모두 받을 수 있습니다. 예를 들어 주문 이벤트 토픽을 실시간 알림 서비스(그룹 A)와 데이터 집계 서비스(그룹 B)가 각각 구독하는 구조가 이에 해당합니다. 파티션은 그룹 단위로 독립 할당되기 때문에 두 그룹은 서로 간섭하지 않습니다.
2. 파티션 리밸런스
리밸런스(Rebalance)는 컨슈머 그룹 내에서 파티션 소유권을 재분배하는 전체 프로세스입니다.
리밸런스가 발생하는 경우
- 새 컨슈머가 그룹에 합류할 때
- 기존 컨슈머가 이탈하거나 크래시가 발생할 때
- 구독 중인 토픽의 파티션 수가 변경될 때
리밸런스 프로토콜의 변화
카프카의 리밸런스 프로토콜은 버전이 올라가면서 크게 세 단계로 발전해 왔습니다.

Eager Rebalance (기존 방식)
리밸런스가 시작되면 모든 컨슈머가 보유한 파티션을 전부 반납합니다. 이후 새로운 할당이 완료될 때까지 전체 컨슈머가 멈추는 Stop-the-world 구간이 발생합니다. RangeAssignor, RoundRobinAssignor, StickyAssignor가 이 방식을 사용합니다.
Cooperative Rebalance (증분 방식, Kafka 2.4+)
이동이 필요한 파티션만 선택적으로 반납하고 재할당합니다. 영향을 받지 않는 파티션의 컨슈머는 계속 동작하므로 Stop-the-world 구간이 사라집니다. CooperativeStickyAssignor가 이 방식을 사용하며, Kafka 3.0부터 기본 Assignor 목록에 포함되었습니다.
Assignor와 리밸런스 프로토콜은 별개 개념입니다.
RangeAssignor는 파티션을 어떻게 나눌지 결정하는 알고리즘이고, Eager/Cooperative는 나누는 과정에서 기존 파티션을 어떻게 처리할지에 관한 프로토콜입니다.CooperativeStickyAssignor는 Sticky 할당 알고리즘 위에 Cooperative 프로토콜을 얹은 것입니다.
그룹 코디네이터와 그룹 리더
리밸런스 과정에는 두 주체가 관여합니다.
- 그룹 코디네이터(Group Coordinator): 브로커에 존재하며, 컨슈머의 합류/이탈을 감지하고 리밸런스를 트리거합니다.
- 그룹 리더(Group Leader): 그룹에 가장 먼저 합류한 컨슈머가 맡습니다. Assignor 알고리즘에 따라 실제 파티션 분배를 계산하고 결과를 코디네이터에 전달합니다.
참고 — KIP-848: 차세대 컨슈머 그룹 프로토콜 (Kafka 4.0 GA)
Kafka 4.0에서 리밸런스 구조 자체가 바뀐 새 프로토콜이 정식 출시되었습니다. 기존에는 그룹 리더(클라이언트)가 파티션을 배분했지만, 새 프로토콜에서는 브로커 측 그룹 코디네이터가 증분 방식으로 직접 할당을 계산합니다. 그룹 리더 개념 자체가 사라지고, 컨슈머는 하트비트로 자신의 상태를 선언한 뒤 브로커의 결정에 따르는 구조입니다. 현재는 옵트인 방식으로
group.protocol=consumer를 설정해야 활성화됩니다.
정적 그룹 멤버십
기본적으로 컨슈머가 그룹을 떠나면 즉시 리밸런스가 시작됩니다. 그러나 group.instance.id를 설정하면 정적 멤버(static member)로 동작하여, 컨슈머가 재시작될 때 session.timeout.ms 시간 내에 복귀하면 기존 파티션 할당을 그대로 유지합니다. 배포나 재시작이 잦은 환경, 또는 로컬 상태(캐시, 집계 결과 등)를 보관하는 컨슈머에서 불필요한 리밸런스를 줄이는 데 유용합니다.
3. KafkaConsumer 생성
컨슈머를 만들려면 최소 네 가지 필수 속성이 필요합니다.
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);| 속성 | 설명 |
bootstrap.servers |
최초 연결할 브로커 목록 (클러스터 전체 목록 불필요, 2개 이상 권장) |
group.id |
컨슈머가 속할 그룹 이름 (subscribe() 사용 시 필수) |
key.deserializer |
키를 바이트 배열에서 객체로 역직렬화할 클래스 |
value.deserializer |
값을 바이트 배열에서 객체로 역직렬화할 클래스 |
bootstrap.servers는 초기 연결용이며, 카프카는 이를 통해 전체 클러스터 메타데이터를 가져옵니다. 브로커가 한 대 다운되어도 다른 브로커로 연결할 수 있도록 2개 이상 지정하는 것을 권장합니다.
4. 토픽 구독
특정 토픽 구독
// 단일 토픽
consumer.subscribe(Collections.singletonList("customer-orders"));
// 여러 토픽 동시 구독
consumer.subscribe(Arrays.asList("orders", "payments", "returns"));정규식으로 구독
토픽 이름 패턴을 정규식으로 지정할 수 있습니다. 패턴에 매칭되는 새 토픽이 생성되면 자동으로 리밸런스가 발생하고 해당 토픽이 구독에 추가됩니다.
consumer.subscribe(Pattern.compile("customer-.*"));MSA 환경에서 서비스별 토픽을 service-name-events 형태로 관리할 때 유용합니다. 다만 새 토픽 생성 시마다 리밸런스가 발생할 수 있고, KIP-848의 서버 사이드 정규식 구독과는 동작 방식이 다르므로 주의가 필요합니다.
5. 폴링 루프
카프카 컨슈머의 핵심 동작은 폴링 루프(Poll Loop)입니다. 컨슈머는 브로커에 주기적으로 레코드를 요청(poll)하고, 반환된 레코드를 처리한 뒤 다시 폴링하는 루프를 반복합니다.
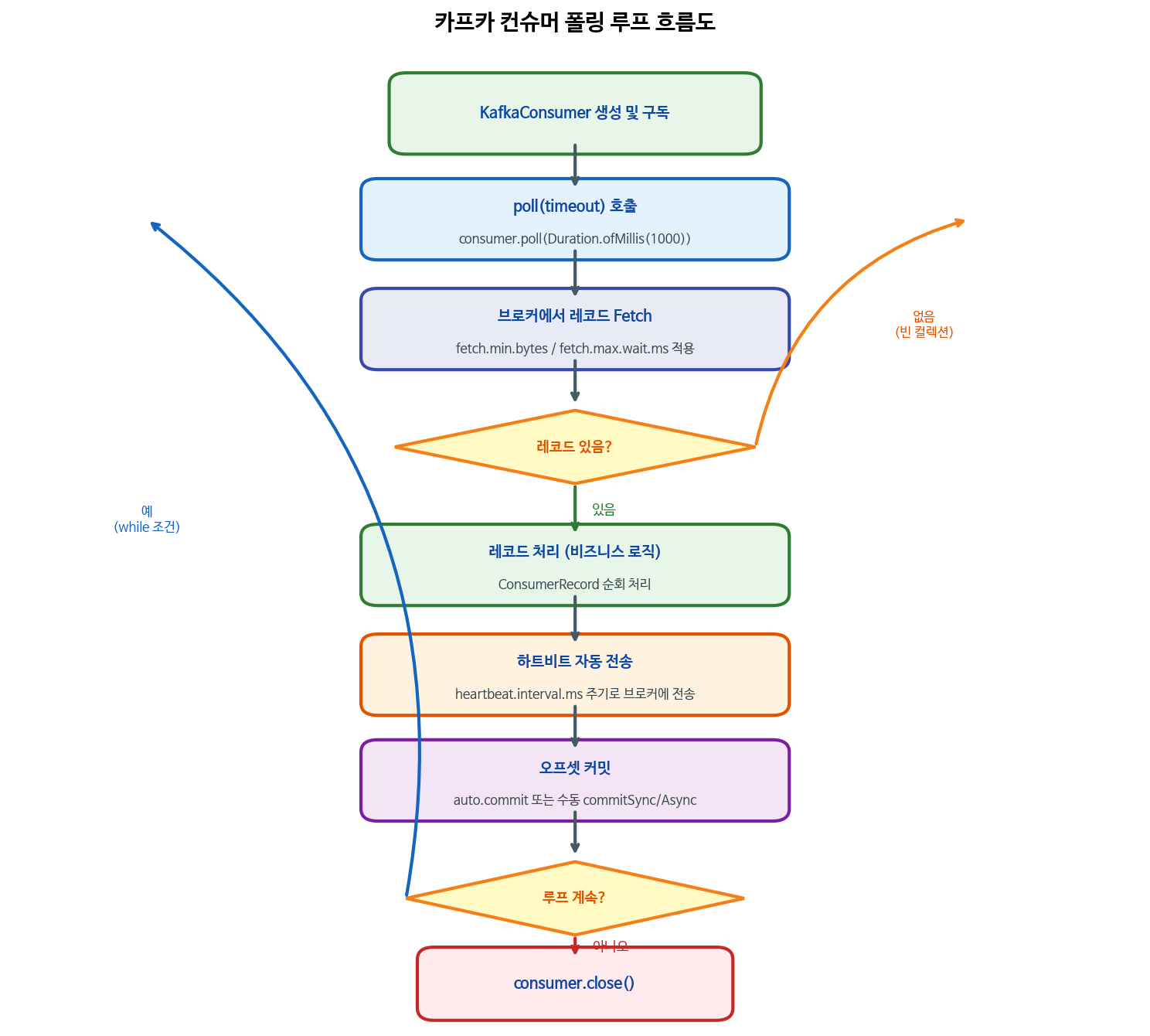
기본 폴링 루프 코드
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic=%s, partition=%d, offset=%d, key=%s, value=%s%n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
}
} finally {
consumer.close(); // 반드시 close() 호출
}poll()의 역할
poll()은 단순히 레코드를 가져오는 것 외에도 여러 작업을 내부적으로 처리합니다.
- 그룹 코디네이터 발견: 최초 호출 시 그룹 코디네이터를 찾고 그룹에 합류합니다.
- 리밸런스 수행: 필요한 경우 리밸런스를 처리합니다.
- 레코드 반환:
max.poll.records설정 수만큼 레코드를 반환합니다.
Kafka 3.x부터 하트비트는 별도 백그라운드 스레드가 담당합니다.
poll()호출과 무관하게heartbeat.interval.ms주기로 전송되며, 브로커는session.timeout.ms안에 하트비트가 오지 않으면 컨슈머가 죽은 것으로 판단합니다.
timeout 파라미터의 의미
poll(Duration.ofMillis(1000))에서 1000ms는 브로커에 레코드가 없을 때 최대 대기할 시간입니다. 레코드가 있으면 즉시 반환하며, 없으면 최대 1초를 기다립니다. 값이 너무 작으면 CPU를 불필요하게 많이 소모하고, 너무 크면 폴링 루프의 응답성이 떨어집니다. 리밸런스 감지 속도는 이 값이 아니라 session.timeout.ms와 heartbeat.interval.ms로 결정됩니다.
스레드 안전성 주의
KafkaConsumer는 스레드 안전하지 않습니다. 하나의 컨슈머 인스턴스는 반드시 하나의 스레드에서만 사용해야 합니다. 멀티스레드로 처리량을 높이려면 컨슈머 인스턴스를 스레드별로 각각 생성하거나, 레코드 수신은 단일 스레드가 담당하고 처리만 워커 스레드에 위임하는 방식을 사용합니다.
max.poll.interval.ms 주의
poll()을 호출하지 않는 구간이 max.poll.interval.ms(기본값 5분)를 초과하면, 브로커는 해당 컨슈머를 죽은 것으로 간주하고 리밸런스를 트리거합니다. 처리 로직이 오래 걸릴 경우 이 값을 늘리거나, 처리 자체를 비동기로 분리하는 것을 고려해야 합니다.
정리
| 개념 | 핵심 내용 |
| 컨슈머 그룹 | 하나의 파티션은 동일 그룹 내 하나의 컨슈머에게만 할당 |
| 컨슈머 수 확장 | 처리량 확장 (상한선은 파티션 수) |
| 그룹 수 확장 | 여러 애플리케이션이 동일 토픽을 독립적으로 소비 |
| Eager Rebalance | 전체 파티션 반납 후 재할당 → Stop-the-world |
| Cooperative Rebalance | 이동 필요한 파티션만 재할당 → 나머지 계속 동작 (Kafka 2.4+) |
| KIP-848 | 할당 주체가 브로커로 이동, 완전 증분 방식 (Kafka 4.0 GA) |
| poll() | 레코드 수신 + 하트비트 + 리밸런스 처리를 모두 담당 |
| 스레드 안전성 | KafkaConsumer는 단일 스레드에서만 사용 |
다음 편 예고: 컨슈머 설정 파라미터 심화, 커밋과 오프셋 관리, 리밸런스 리스너를 다룹니다.
'Data > Kafka' 카테고리의 다른 글
| [Kafka] 카프카 컨슈머: 종료, 역직렬화, 독립 실행 (0) | 2026.06.07 |
|---|---|
| [Kafka] 카프카 컨슈머: 설정과 오프셋 관리 (0) | 2026.06.07 |
| [Kafka] 카프카 프로듀서 완전 정복 2편 — 설정, 파티션 전략, 인터셉터, 쿼터 (0) | 2026.06.04 |
| [Kafka] 카프카 프로듀서 완전 정복 1편 — 구조, 전송, 시리얼라이저 (0) | 2026.06.04 |
| [Kafka] 운영 환경 세팅 가이드 — OS / 디스크 / 네트워크 튜닝 (0) | 2026.06.03 |



