이 글은 Apache Kafka Java Client 3.7.x 기준으로 작성되었습니다.
1편에서 프로듀서의 구성 요소와 전송 방식을 다뤘습니다. 2편에서는 프로듀서 동작에 직접 영향을 미치는 설정값과 고급 기능을 살펴봅니다.
1. 주요 설정
프로듀서 설정은 크게 신뢰성과 처리량 두 축 사이의 트레이드오프로 이해할 수 있습니다. 신뢰성을 높이면 브로커 응답을 더 많이 기다려야 하므로 처리량이 낮아지고, 처리량을 높이면 그만큼 유실 가능성이 생깁니다. 어느 쪽에 무게를 두느냐는 서비스 특성에 따라 달라집니다.
1-1. acks — 신뢰성의 핵심
acks는 브로커가 메시지를 수신했다고 판단하는 기준을 설정합니다. 프로듀서 설정 중 메시지 유실 가능성에 가장 직접적인 영향을 미칩니다.

| 값 | 동작 | 유실 위험 | 처리량 |
0 |
브로커 응답 대기 없음 | 높음 | 최고 |
1 |
Leader 저장 확인 후 ACK | 중간 (Follower 복제 전 장애 시 유실) | 중간 |
all (-1) |
ISR 전체 복제 완료 후 ACK | 낮음 | 낮음 |
acks=all을 사용할 때는 브로커의 min.insync.replicas와 함께 설정해야 실질적인 내구성이 보장됩니다. 예를 들어 복제 팩터가 3이고 min.insync.replicas=2이면, ISR에 최소 2개의 브로커가 있어야 쓰기가 허용됩니다.
props.put(ProducerConfig.ACKS_CONFIG, "all");프로덕션 권장:
acks=all+min.insync.replicas=2+replication.factor=3조합이 일반적인 기준입니다.
1-2. retries / delivery.timeout.ms — 재시도 제어
카프카 프로듀서는 일시적인 브로커 오류(리더 선출 중, 네트워크 단절 등)에 대해 자동으로 재시도합니다.
// 재시도 횟수보다 전체 타임아웃으로 제어하는 것이 권장됨
props.put(ProducerConfig.DELIVERY_TIMEOUT_MS_CONFIG, 120_000); // 기본 120초
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE); // 사실상 무제한
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 100); // 재시도 간격 (ms)retries를 직접 제어하기보다 delivery.timeout.ms 안에서 재시도가 반복되는 구조로 이해하는 것이 정확합니다. 타임아웃이 소진되면 그때 콜백의 exception으로 전달됩니다.
| 설정 | 기본값 | 역할 |
retries |
Integer.MAX_VALUE (Kafka 2.1+) |
재시도 최대 횟수 |
retry.backoff.ms |
100ms |
재시도 간격 |
delivery.timeout.ms |
120,000ms |
send() 호출부터 최종 성공/실패까지 허용 시간 |
1-3. batch.size / linger.ms / buffer.memory — 처리량 최적화
프로듀서는 메시지를 하나씩 보내지 않고 배치로 묶어서 전송합니다. 이 동작을 제어하는 세 가지 설정이 서로 맞물려 작동합니다.
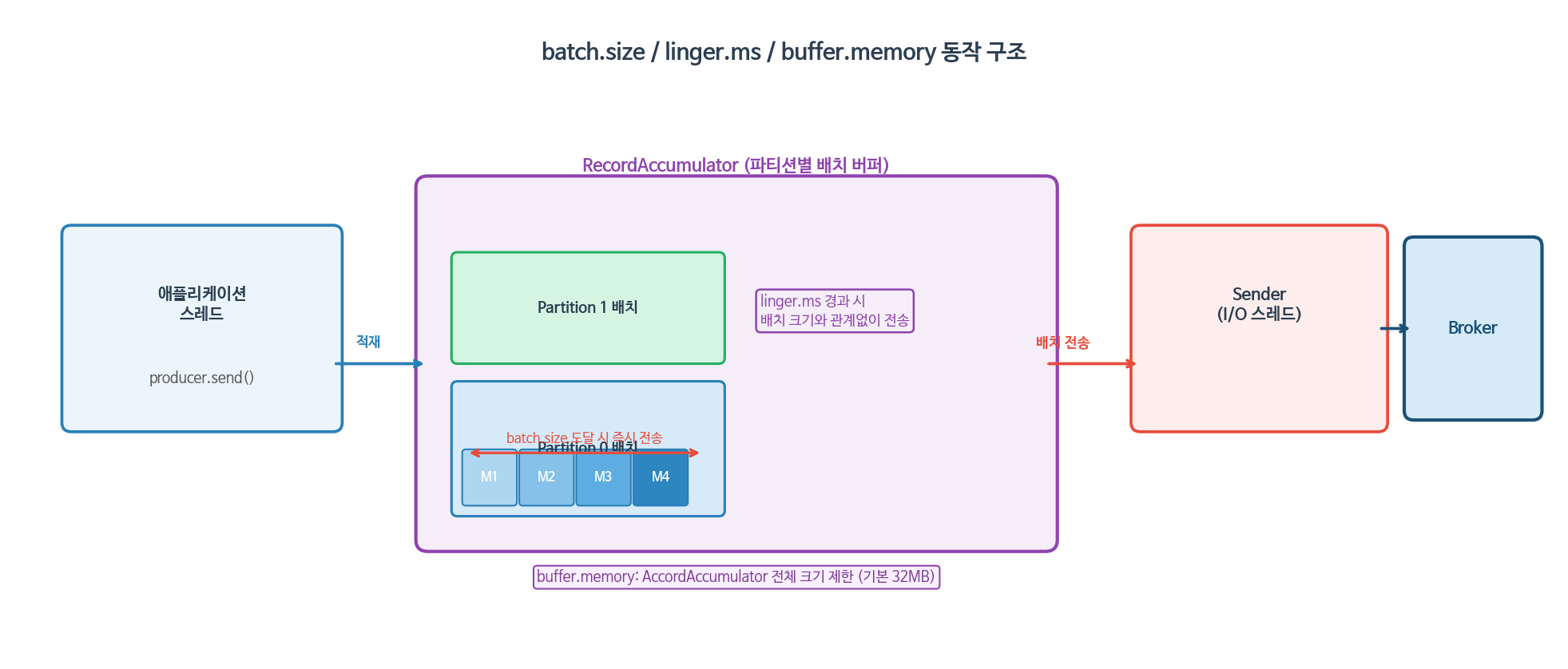
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16_384); // 배치 최대 크기 (bytes), 기본 16KB
props.put(ProducerConfig.LINGER_MS_CONFIG, 5); // 배치 대기 시간 (ms), 기본 0
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33_554_432);// 버퍼 전체 크기 (bytes), 기본 32MBbatch.size: 파티션별 배치가 이 크기에 도달하면 즉시 전송합니다. 크게 설정할수록 처리량이 오르지만 메모리 사용량도 증가합니다.linger.ms: 배치가 꽉 차지 않아도 이 시간이 경과하면 전송합니다. 기본값은0(대기 없음)이며,5~20ms수준으로 늘리면 처리량이 크게 향상됩니다.buffer.memory:RecordAccumulator전체 크기 제한입니다. 버퍼가 가득 차면send()호출이max.block.ms(기본 60초) 동안 블로킹되고, 이후에도 해소되지 않으면 예외가 발생합니다.
튜닝 팁: 처리량을 높이려면
linger.ms를 약간 늘리는 것이 가장 간단하고 효과적입니다.batch.size는 메시지 평균 크기를 고려해 배치당 수십~수백 개의 메시지가 묶이도록 조정합니다.
1-4. max.in.flight.requests.per.connection — 순서 보장과의 관계
이 설정은 ACK를 받지 않은 상태에서 브로커에 동시에 전송할 수 있는 요청 수입니다.
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5); // 기본값
값이 클수록 처리량이 높아지지만, 재시도가 발생했을 때 메시지 순서가 뒤바뀔 수 있습니다. 순서 보장이 필요하다면 1로 설정하거나, enable.idempotence=true를 활성화하면 5까지 유지하면서도 순서가 보장됩니다.
enable.idempotence는 다음 섹션에서 자세히 다룹니다.
| 설정 조합 | 순서 보장 | 처리량 |
max.in.flight=1 |
보장 | 낮음 |
max.in.flight=5 + enable.idempotence=false |
미보장 (재시도 시) | 높음 |
max.in.flight=5 + enable.idempotence=true |
보장 | 높음 |
| max.in.flight=6 이 + enable.idempotence=true | ConfigException — 프로듀서 생성 불가 | - |
enable.idempotence=true일 때 max.in.flight 상한이 5인 이유는 브로커의 시퀀스 번호 추적 윈도우 크기가 파티션당 최대 5로 고정되어 있기 때문입니다.
브로커는 (PID, 파티션)별로 최근 5개의 시퀀스 번호만 기억하고, 이 범위를 벗어난 재시도가 오면 중복 여부를 판단할 수 없습니다.
따라서 in-flight이 6 이상이면 이 보장이 깨지므로, 카프카는 아예 프로듀서 초기화 시점에 ConfigException을 던져 시작을 막습니다.
1-5. enable.idempotence — 중복 방지
enable.idempotence=true를 설정하면 프로듀서가 각 메시지에 시퀀스 번호를 부여합니다. 브로커는 이를 이용해 재시도로 인한 중복 메시지를 자동으로 걸러냅니다.
Kafka 3.0부터 enable.idempotence의 기본값이 true로 변경되었습니다. 즉, 3.7.x 기준으로는 별도 설정 없이도 멱등성이 활성화되어 있습니다.
// Kafka 3.0+ 기본값이 true이므로 명시적 설정은 의도를 드러내기 위한 목적
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
활성화 시 아래 설정이 자동으로 강제됩니다.
| 설정 | 강제값 |
acks |
all |
retries |
Integer.MAX_VALUE |
max.in.flight.requests.per.connection |
≤ 5 |
주의:
enable.idempotence는 프로듀서 → 브로커 구간의 중복만 방지합니다. 컨슈머가 같은 메시지를 두 번 처리하는 문제는 컨슈머 측에서 별도로 처리해야 합니다.
1-6. compression.type — 압축
네트워크 대역폭을 줄이고 처리량을 높이는 데 효과적입니다.
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy"); // none, gzip, snappy, lz4, zstd| 알고리즘 | 압축률 | CPU 부하 | 적합한 상황 |
gzip |
높음 | 높음 | 대역폭 제한, 비용 민감 환경 |
snappy |
중간 | 낮음 | 범용 (Google 권장) |
lz4 |
중간 | 매우 낮음 | 지연에 민감한 환경 |
zstd |
높음 | 중간 | 높은 압축률 + 적당한 CPU |
2. 파티션 전략
파티션 전략은 메시지가 어느 파티션으로 들어갈지를 결정합니다. 순서 보장, 처리량 균형, 비즈니스 로직 반영 여부에 직접 영향을 미칩니다.

2-1. 키 없음 — Sticky Partitioner (기본)
Kafka 2.4 이후 기본 파티셔너는 Sticky Partitioner입니다. 키가 없는 메시지를 배치가 전송될 때까지 하나의 파티션에 몰아서 보내고, 이후 다음 파티션으로 전환합니다. 이전 방식(라운드로빈)보다 배치 효율이 높습니다.
2-2. 키 있음 — 해시 기반
키가 있으면 murmur2(key) % numPartitions로 파티션을 결정합니다. 같은 키는 항상 같은 파티션으로 들어가므로, 특정 사용자나 주문 단위의 순서 보장이 필요할 때 사용합니다.
// 같은 orderId는 항상 같은 파티션
new ProducerRecord<>("orders", orderId, orderJson);주의: 파티션 수를 변경하면 키 → 파티션 매핑이 달라집니다. 이미 운영 중인 토픽의 파티션 수 변경은 순서 보장에 영향을 주므로 신중해야 합니다.
2-3. 커스텀 파티셔너
비즈니스 규칙에 따라 파티션을 직접 결정하려면 Partitioner 인터페이스를 구현합니다.
public class PriorityPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
int numPartitions = cluster.partitionCountForTopic(topic);
// 키가 없으면 파티션 0 이후로 균등 분산
if (keyBytes == null) {
return (int) (Math.random() * (numPartitions - 1)) + 1;
}
// VIP 키는 파티션 0으로 고정
if (new String(keyBytes).startsWith("VIP-")) {
return 0;
}
// 그 외는 1번 파티션부터 분산
return (Utils.murmur2(keyBytes) & Integer.MAX_VALUE) % (numPartitions - 1) + 1;
}
@Override public void configure(Map<String, ?> configs) {}
@Override public void close() {}
}props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, PriorityPartitioner.class.getName());
3. 인터셉터
프로듀서 인터셉터는 메시지가 직렬화되기 전과 ACK를 받은 후 두 시점에 공통 로직을 끼워 넣는 수단입니다. 애플리케이션 코드를 수정하지 않고 횡단 관심사(cross-cutting concern)를 처리할 수 있습니다.
send() 호출
→ onSend() ← 인터셉터 개입 (직렬화 전)
→ Serializer
→ Partitioner
→ RecordAccumulator
→ Sender → Broker
→ onAcknowledgement() ← 인터셉터 개입 (ACK 수신 후)
→ Callback
주요 활용 사례
- 모든 메시지에 트레이싱 헤더 자동 추가
- 전송 성공/실패 메트릭 수집
- 특정 토픽 메시지 로깅
public class TracingInterceptor implements ProducerInterceptor<String, String> {
// 실제 구현에서는 Micrometer, Prometheus 등 메트릭 라이브러리를 주입받아 사용
private MeterRegistry meterRegistry;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 모든 메시지에 trace-id 헤더 자동 삽입
record.headers().add("trace-id",
UUID.randomUUID().toString().getBytes(StandardCharsets.UTF_8));
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception != null) {
meterRegistry.counter("kafka.send.failure").increment();
} else {
meterRegistry.counter("kafka.send.success").increment();
}
}
@Override public void close() {}
@Override public void configure(Map<String, ?> configs) {}
}props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingInterceptor.class.getName());
여러 인터셉터를 쉼표로 연결하면 등록 순서대로 체인으로 실행됩니다.
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"com.example.TracingInterceptor,com.example.MetricsInterceptor");주의:
onSend()에서 예외가 발생하면 메시지 전송이 중단될 수 있습니다. 인터셉터 내부에서는 반드시 예외를 잡아 처리해야 합니다.
4. 쿼터와 스로틀링
카프카 브로커는 특정 클라이언트가 과도한 네트워크 대역폭이나 CPU를 사용하지 못하도록 쿼터(Quota)를 설정할 수 있습니다. 쿼터를 초과한 클라이언트는 브로커로부터 스로틀링(Throttling) 응답을 받습니다.
4-1. 쿼터 설정 (브로커 측)
쿼터는 프로듀서의 client.id 단위로 적용됩니다. 먼저 프로듀서에 식별자를 부여하고,
props.put(ProducerConfig.CLIENT_ID_CONFIG, "my-producer");브로커에서 해당 client.id에 쿼터를 설정합니다.
# 특정 클라이언트 ID에 쓰기 대역폭 제한 설정 (10MB/s)
kafka-configs.sh --bootstrap-server localhost:9092 \
--alter --add-config 'producer_byte_rate=10485760' \
--entity-type clients --entity-name my-producer4-2. 스로틀링 동작 원리
쿼터를 초과하면 브로커가 프로듀서에게 대기 시간(throttle time)을 응답으로 내려보냅니다. 프로듀서는 이 시간 동안 추가 요청을 멈추고 대기합니다. 애플리케이션 코드 변경 없이 브로커가 자동으로 속도를 제어합니다.
4-3. 스로틀링 모니터링
스로틀링이 발생하고 있는지는 프로듀서 메트릭으로 확인할 수 있습니다.
// KafkaProducer 메트릭에서 확인
Map<MetricName, ? extends Metric> metrics = producer.metrics();
metrics.forEach((name, metric) -> {
if (name.name().contains("throttle")) {
System.out.printf("%s = %s%n", name.name(), metric.metricValue());
}
});
주요 확인 메트릭:
| 메트릭 | 설명 |
produce-throttle-time-avg |
평균 스로틀링 대기 시간 (ms) |
produce-throttle-time-max |
최대 스로틀링 대기 시간 (ms) |
스로틀링이 지속적으로 발생한다면 쿼터 한도 상향 또는 프로듀서 인스턴스 분산을 검토해야 합니다.
정리
| 주제 | 핵심 |
acks |
0 / 1 / all — 신뢰성과 처리량의 트레이드오프. 프로덕션은 all 권장 |
| 재시도 | retries 횟수보다 delivery.timeout.ms로 전체 시간 제어 |
| 배치/버퍼 | batch.size + linger.ms로 처리량 조정. buffer.memory 초과 시 블로킹 |
| 순서/중복 | enable.idempotence=true로 프로듀서 → 브로커 구간 중복 방지 + 순서 보장 |
| 파티션 전략 | 키 없음(Sticky) / 키 있음(해시) / 커스텀 — 서비스 요건에 따라 선택 |
| 인터셉터 | onSend() / onAcknowledgement() 두 시점에 공통 로직 삽입 |
| 쿼터/스로틀링 | 브로커 측 설정. produce-throttle-time-avg 메트릭으로 모니터링 |
이것으로 카프카 프로듀서의 주요 내용을 모두 살펴봤습니다. 다음 편에서는 카프카 컨슈머의 구조와 동작 방식을 다룹니다.
'Data > Kafka' 카테고리의 다른 글
| [Kafka] 카프카 컨슈머: 설정과 오프셋 관리 (0) | 2026.06.07 |
|---|---|
| [Kafka] 카프카 컨슈머: 개념과 동작 원리 (0) | 2026.06.07 |
| [Kafka] 카프카 프로듀서 완전 정복 1편 — 구조, 전송, 시리얼라이저 (0) | 2026.06.04 |
| [Kafka] 운영 환경 세팅 가이드 — OS / 디스크 / 네트워크 튜닝 (0) | 2026.06.03 |
| [Kafka] 브로커 핵심 매개변수 레퍼런스 (0) | 2026.06.03 |



